


Laziness is a Superpower
...or how I dodged weeks of soul-rending tedium with some clever Python


When confronted with having to do a thing, nobody in this world will work harder than a lazy person to not do that thing.
In October, I published the 5th edition of Professional JavaScript for Web Developers, and I’m reminded of a disaster that I averted when publishing the previous edition in 2019.
The 4th edition was a 1,200 page monstrosity that took me the better part of two years to revise. Upon finishing the book revisions and editing process, I was utterly horrified to receive this email from my editor:
Hi Matt,
Please let me know how you would like to submit all the code snippets from the book.
I had completely overlooked the eventual need to extract all the example code snippets in the book and provide them for readers to download.
Professional JavaScript has thousands of code snippets and examples, most of which are unnamed blocks of inline code. Here’s one example page from the Async/Await chapter:

Without a clever workaround, I was doomed to spend weeks copying and pasting example after example out of the drafts.
As a lazy person, I was determined to not do the thing.
Extracting XML
The book draft was written in Microsoft Word .docx files with a special publisher template, one file for each chapter. I knew that all .docx files are essentially ZIP files containing XML and other files used by Microsoft Word, so they could be extracted using any standard unzip utility. If I could figure out a reliable way of parsing and extracting code snippets from that XML, the lazy man might yet prevail.
I fired up a terminal and ran unzip c11_revised.docx to see what I’d get back:
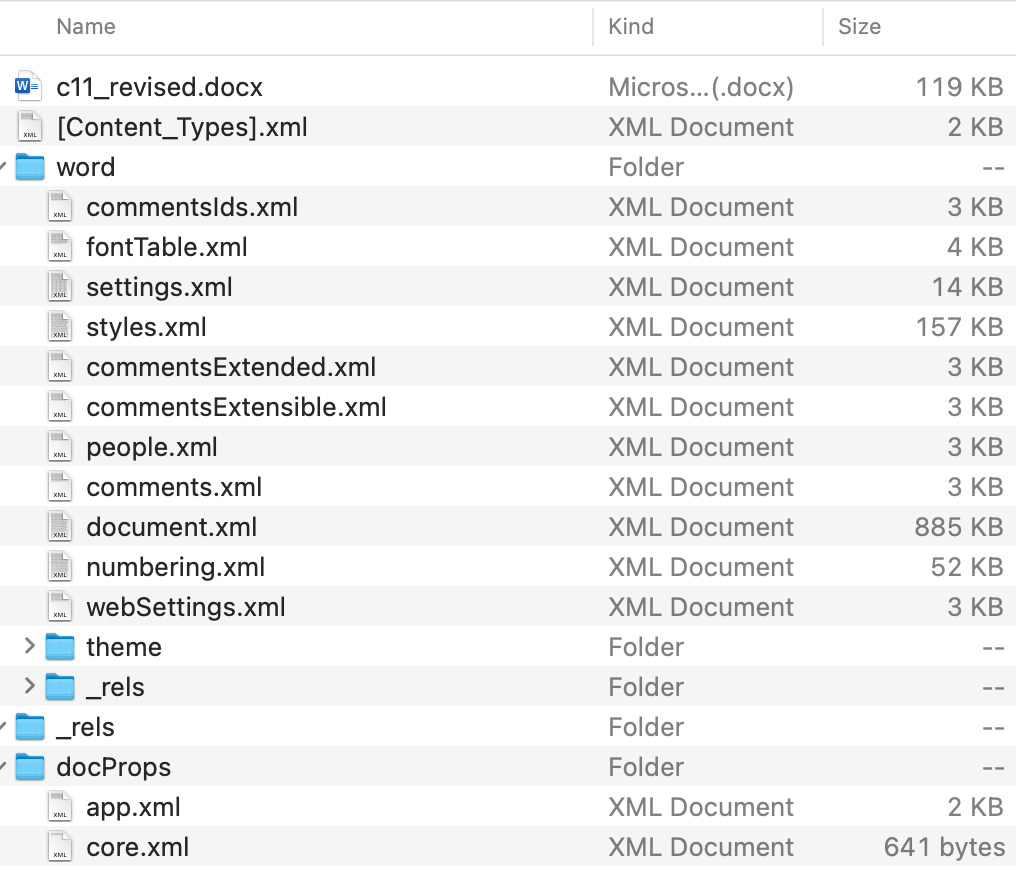
Seems promising. Let’s see what the code snippet from above looks like in word/document.xml:
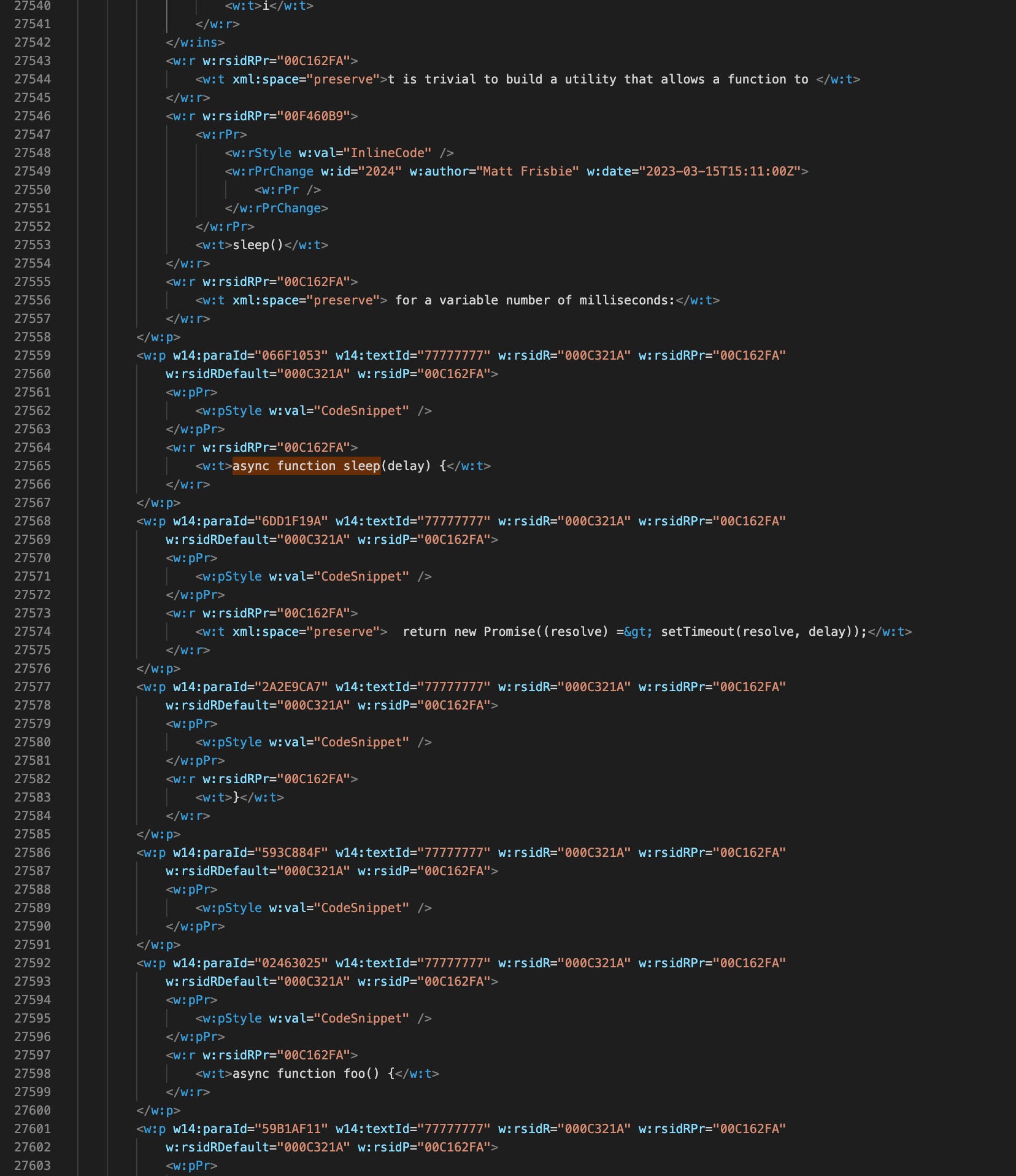
Looks like the code snippets are broken into long sequences of nested elements, but each contains an element with the attribute w:val="CodeSnippet" .
A plan emerges: any consecutive XML elements containing w:val="CodeSnippet" could be stitched together into a single string until a w:val attribute NOT equal to CodeSnippet was encountered. This joined string would be recorded as the full code snippet - with formatting preserved, since the whitespace is included.
File Extensions
The book’s snippets were predominantly JavaScript, but there were some HTML files sprinkled throughout the book - and none were directly identified by an HTML filename.
Fortunately, the HTML files were so simplistic that I could just check the snippet string for HTML elements to determine the file extension.
Naming Things
But what to name the damn files? The snippets are just code floating around in the page. Thankfully, the publisher’s template offered a solution: the header hierarchy.
In the process of writing the book, I’d dutifully stuck to the header styles, since this allows the table of contents to be easily generated.

In doing so, the underlying XML had a hierarchy of attributes denoting chapter titles, sections, and subsections that I would be able to extract.
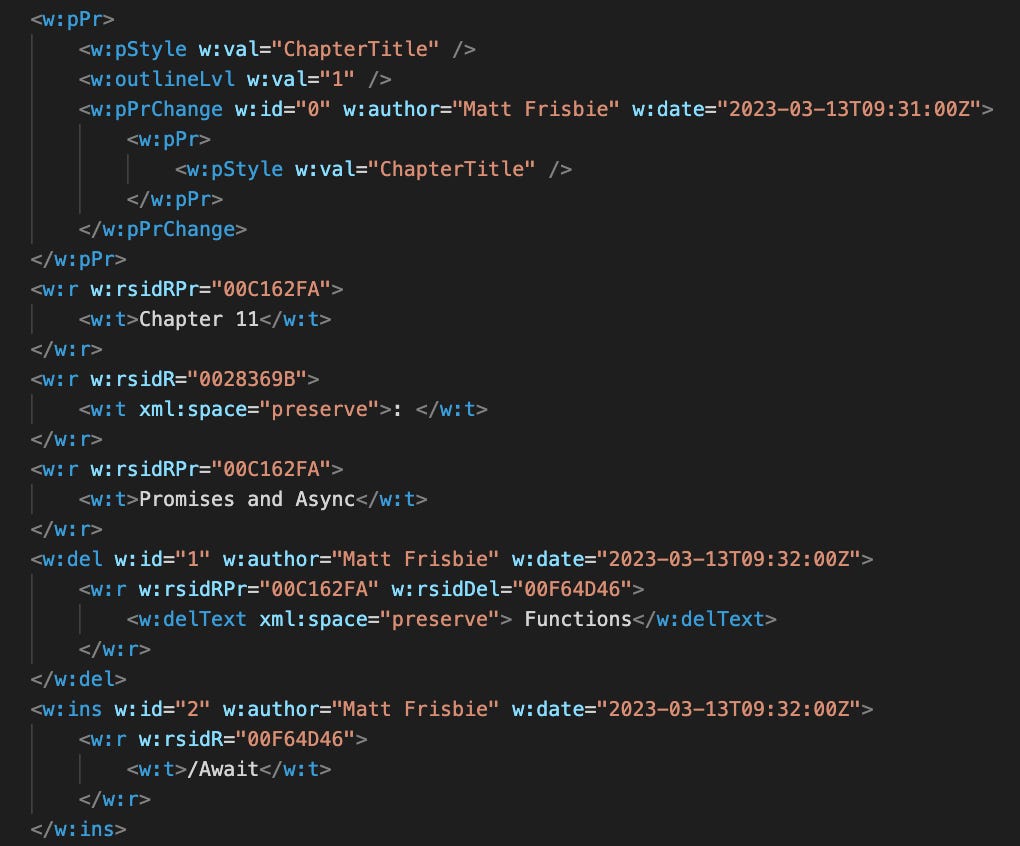
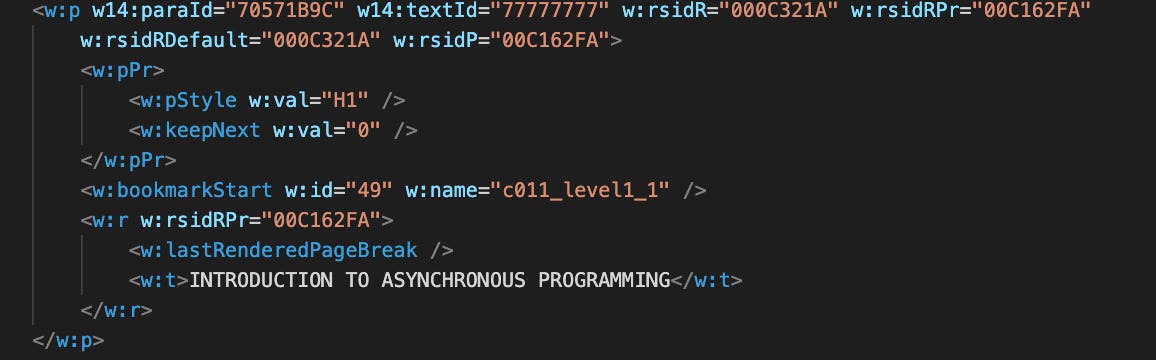
Smells like a directory/file structure to me!
Assuming I could iteratively parse the XML, track the current hierarchy as I traversed to each code snippet, and also track the ordinality of that snippet, I’d be able to strip out the whitespace and special characters to generate something like this:
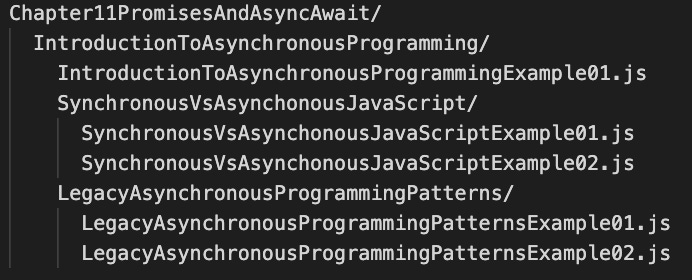
Writing the Extractor
Python includes the excellent xml.etree.ElementTree package, which allows us to traverse an entire XML document depth-first with a simple root.iter():
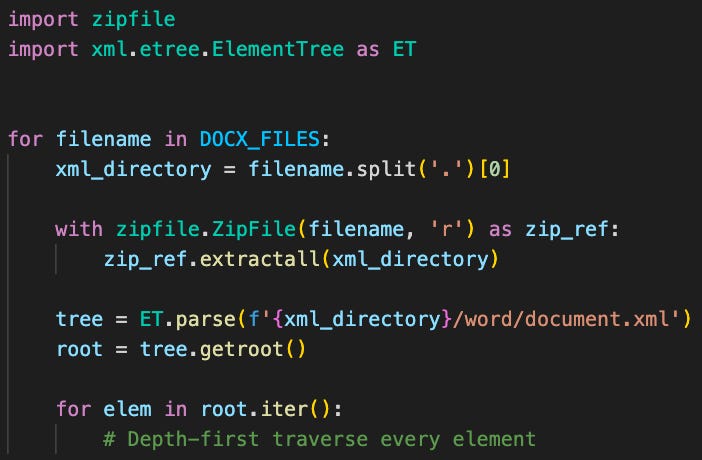
Using the process described above, I threw together this python script and fired it up. The thrill of seeing it fire out 1,836 neatly organized files in about 5 seconds cannot be overstated.
I pushed the lot up to GitHub and casually replied to my editor with a link to the repo, pretending this was the plan all along.
The lazy man lives to fight another day.
Great. But it's better if you used JavaScript for the JavaScript book.
Great read! A lot of people would benefit from knowing a little programming for personal custom use cases like these :)